Prompting just split into 4 disciplines - and most of us only know one
📺 This article is based on a YouTube video by Nate B. Jones:
Prompting just split into 4 different disciplines
What follows is an extended analysis, commentary, and practical takeaways built on that material.
TL;DR
- Prompting in 2026 is not a single skill - it’s four distinct disciplines that build on each other like layers of a stack.
- Prompt craft is now the minimum standard - like knowing how to type.
- Context engineering decides 99.98% of what the model “sees” - and that’s where the real difference is made.
- Intent engineering tells agents what they should want - without it, even perfect context leads to bad outcomes.
- Spec engineering is the top level - writing documents that autonomous agents can execute over days and weeks.
- The gap between people who know all four disciplines and those who know one is already 10x - and growing.
🚀 Intro: If you’re prompting like you did a month ago, you’re already behind
Sounds like clickbait? I get the skepticism. I’d roll my eyes too if I read a headline like this a year ago. But take a moment to think about what’s happened in the last few weeks.
Opus 4.6, Gemini 3.1 Pro, GPT 5.3 Codex - each of these models showed up almost simultaneously, and each can work autonomously for hours, days, and sometimes even weeks. It’s no longer about “answering questions better.” They execute complex specifications without constantly checking in with you. They behave like independent employees: you give them a task in the morning and pick up the result in the evening.
And that changes everything about what it means to be “good at prompting.”
Because here’s the thing - the word “prompting” now hides four entirely different skill sets. Most of us only practice one of them - the most basic one. And the gap between people who see all four and those who see one? It’s already 10x. And it widens every week.
Nate B. Jones, the author of the material I’m building on here, put it well: this isn’t a world that’s coming. This is a world that has already landed. TELUS reports 13,000 custom AI solutions internally. Zapier has more than 800 agents. And these are the companies that chose to talk about it publicly - the ones that take AI really seriously probably have an order of magnitude more and feel no need for press releases.
📊 The 10x gap: same model, same Tuesday, different results
So I’m not just hand-waving, let me use an example from Nate’s material that illustrates the scale of the problem beautifully. It’s simple but brutally effective.
Imagine an ordinary Tuesday morning. Two people sit down at the same AI model. Same subscription, same context window, same access to tools. The only difference? Prompting skills.
Person A - 2025 skills
Types a prompt: “Make me a PowerPoint about Q3 results.” Gets back something roughly 80% correct. The fonts clash, the formatting needs tweaks, several slides are redundant. Spends 40 minutes fixing it. They’re happy - this presentation would normally take 2-3 hours. They saved maybe 60% of the time. Not bad.
Person B - 2026 skills
Spends 11 minutes writing a structured specification. Defines exactly: how many slides, what visual style, what data from what source, what quality criteria, what “done” looks like. Hands it to the same model - but thinks of it as an autonomous agent, not a chat partner. Goes to make coffee. Comes back to a finished presentation that meets every standard defined up front. Before lunch they do the same for five more presentations.
A week’s work in one morning.
| Person A (2025) | Person B (2026) | |
|---|---|---|
| Time on the prompt | 2 minutes | 11 minutes |
| First-output quality | ~80% | ~98% |
| Time fixing it | 40 minutes | ~0 minutes |
| Presentations before lunch | 2-3 | 5-6 |
| Savings vs. manual work | ~60% | ~95% |
Same model. Same Tuesday. 10x gap.
And here’s what’s crucial - Person B isn’t smarter or more technical. They simply practice a different skill that Person A doesn’t even know exists. Person A optimizes the prompt. Person B optimizes the specification. These are fundamentally different approaches.
🧠 Toby Lütke and communication as the foundation of everything
Before we get into the four-discipline framework itself, it’s worth pausing on a fascinating perspective from the CEO of Shopify - Toby Lütke. Unlike many heads of large companies, Toby is a technical guy who doesn’t engage with AI only through the lens of LinkedIn. He keeps a folder of prompts he runs against every new model release. He thinks really deeply about how new models change his daily workflow.
Toby uses the term “context engineering” and defines it in a way I find extraordinarily elegant:
The ability to articulate a problem with enough context that, without any additional information, the task becomes plausibly solvable.
Read that again. This isn’t about clever prompt tricks. Not about magic words. It’s about communication discipline. Can you state a problem so completely, with so much relevant information, that a capable system - AI or human - can solve it without going out to fetch more context?
But Toby went further and noticed something fascinating. Ever since he started supplying AI with full context, he’s become a better communicator as CEO. His emails are tighter, his notes sharper, his decision frameworks stronger. AI forced a discipline on him that carried over into communication with humans.
And he advanced a provocative thesis worth thinking about:
Much of what people in large companies call “politics” is, in reality, bad context engineering for humans.
Misunderstandings about assumptions that are never made explicit but play out as grievances, conflicts and political games. If people communicated with the precision AI demands, many of these problems simply wouldn’t exist.
This is a deep insight we’ll come back to at the end of the article. Because it turns out that prompting AI teaches us something fundamental about human-to-human communication.
🏗️ The four-discipline framework - the full picture
OK, time for the meat. Here’s the framework that, in my view, best describes what prompting should be in 2026. Nate built it to be future-proof, and looking at the trajectory of agents, it’s hard to disagree.
Each discipline operates at a different “altitude” and on a different time horizon. They build on each other - if you skip one, you create a structural weakness in your approach to AI. This isn’t a ladder you can drop the lower rungs from. It’s a stack, where each layer enables the layers above.
┌─────────────────────────────────────────────┐
│ 4. SPEC ENGINEERING │ ← Organization / Weeks
│ Agent-readable documents │
├─────────────────────────────────────────────┤
│ 3. INTENT ENGINEERING │ ← Strategy / Days
│ Goals, values, decision boundaries │
├─────────────────────────────────────────────┤
│ 2. CONTEXT ENGINEERING │ ← Session / Hours
│ Curating the optimal tokens │
├─────────────────────────────────────────────┤
│ 1. PROMPT CRAFT │ ← Interaction / Minutes
│ Clear instructions, examples, format │
└─────────────────────────────────────────────┘Let’s look at each one in detail.
🔨 Discipline 1: Prompt craft - once the whole game, now the minimum standard
This is the original prompting skill. The one we’ve been learning for the past two years on courses, on blogs, and in the docs from Anthropic, OpenAI and Google. It is synchronous, session-based and individual.
You sit in front of a chat window. You write an instruction. You evaluate the result. You iterate. You get better at formulating things, you supply examples, you structure instructions. If you’ve been following the topic for a while, you’ve probably built real skill here. And it works - you’re faster than you were a year ago.
What goes into good prompt craft?
- ✅ Clear instructions - precise, unambiguous commands
- ✅ Relevant examples and counter-examples - showing the model what you want and what you don’t
- ✅ Guardrails - boundaries the model shouldn’t cross
- ✅ Explicit output format - describing exactly what the result should look like
- ✅ Resolving ambiguity - defining what to do in conflicting situations
This is the foundation. It’s on a thousand blogs and LinkedIn courses. And it’s absolutely necessary.
But notice: prompt craft hasn’t become irrelevant - it’s become the minimum standard.
Nate compares it to the skill of touch-typing. Once it was a professional differentiator - secretaries who typed fast were worth their weight in gold. Today? It’s simply an assumed skill. Nobody puts it on their CV.
If you can’t write a clear, well-structured prompt in 2026, you’re like someone from 1998 who couldn’t send an email.
Is it important to know how? Yes.
Will it set you apart in the job market? No, not really.
Why the prompt alone is no longer enough
Prompt craft was the whole game when AI interactions were synchronous and session-based. You’d write something, get a response, refine in real time. You were simultaneously the intent layer, the context layer and the quality layer. You caught errors, supplied missing context, corrected course when things started drifting.
That model broke the moment agents started running for hours - sometimes days - without checking in with you. Everything you relied on in conversation must now be encoded before the agent starts working. Not mid-conversation, but at the very beginning.
And this is fundamentally a different skill. Not a harder version of the same skill - actually different.
🌐 Discipline 2: Context engineering - 99.98% of what the model sees
Anthropic published a foundational piece on context engineering in September 2025, but it’s only now, in early 2026, that we’re seeing the full consequences of this approach. Context engineering is the shift from crafting a single instruction to curating the entire information environment an agent operates in.
The definition I take from Nate: context engineering is the set of strategies for curating and maintaining the optimal set of tokens during an LLM’s task.
To see why this matters, look at the proportions:
- Your prompt might be 200 tokens
- The context window it lands in might be one million tokens
- Your 200 tokens are 0.02% of what the model sees
- The remaining 99.98% - that’s context engineering
That 99.98% isn’t empty noise. It’s specific elements that shape the model’s behavior:
| Element | What it does | Example |
|---|---|---|
| System prompts | Define agent behavior | ”You are a UX expert…” |
| Tool definitions | Describe available APIs and functions | MCP specs, function calling |
| Retrieved documents | Supply domain knowledge | RAG, project files, docs |
| Message history | Conversation context | Previous turns of dialogue |
| Memory systems | Long-term agent memory | Vectors, knowledge bases |
| MCP connections | External data sources | APIs, databases, company systems |
This is the discipline that produces claude.md files, agent specifications, RAG pipelines, memory architectures. It decides whether a coding agent understands your project’s conventions, whether a research agent has access to the right documents, whether a customer-support agent can pull the right account history.
Anthropic’s key insight: more ≠ better
Anthropic’s engineering team identified the main challenge precisely: LLMs degrade when you give them more information. Retrieval quality drops as context grows. This is counterintuitive - it feels like the more context we give the model, the better. But in practice the goal is to include the right tokens and keep the wrong ones away.
It’s like the difference between a desk piled with paper and a desk on which exactly the documents you need for the current task are laid out. Both desks “have information,” but only one lets you work effectively.
The practical implication - and this is the key
The people who are 10x more effective with AI than their peers don’t write 10x better prompts. They build 10x better context infrastructure.
Their agents start every session with the right project files, the right conventions, the right constraints already loaded. The prompt itself can be relatively simple, because context does the heavy lifting.
Harrison Chase from LangChain confirmed this outright in an interview with Sequoia Capital: “Everything is context engineering. It actually describes everything we’ve been doing at LangChain without knowing this term existed.”
And here a certain danger appears - people have started treating context engineering as a synonym for “everything we do with AI.” But it’s only one of the four levels. Important, foundational, but not the only one.
🎯 Discipline 3: Intent engineering - what the agent should want
This is the discipline that’s still talked about too little, and which becomes critical as agents take on longer autonomous tasks.
The distinction is subtle but fundamental:
- Context engineering tells agents what to know
- Intent engineering tells agents what to want
It’s the practice of encoding organizational purpose - your goals, values, trade-off hierarchies, decision boundaries - into the infrastructure agents act against. In other words: it isn’t enough to give an agent information. You have to tell it what’s important, what is more important than what, and when it should stop and ask.
The Klarna case: a textbook failure of intent engineering
The Klarna story is one of the most famous cases of a missing intent layer leading to disaster. Their AI agent resolved 2.3 million customer conversations in the first month. On paper - a spectacular success.
The problem? The agent optimized for shortening resolution time (because that’s how it was configured), but not for customer satisfaction (because no one encoded that as a priority). The result? Fast but soulless replies. Customers felt ignored. Klarna ran into serious trouble, had to rehire many human agents, and is still dealing with the trust fallout.
Perfect context + terrible intent alignment = company-scale disaster.
It wasn’t a technical problem. It was a problem of communicating goals. No one told the agent: “customer satisfaction is more important than resolution speed.” No one encoded the trade-off hierarchy.
Where intent sits in the stack
Intent engineering sits above context engineering the way strategy sits above tactics:
- ✅ You can have perfect context and terrible intent alignment - the agent knows everything but pursues the wrong goal
- ❌ You can’t have good intent alignment without good context - the agent needs information to act on intent
The disciplines are cumulative. And crucially - the consequences of failure grow as you move up the hierarchy:
| Level of failure | Scale of consequences | Example |
|---|---|---|
| Bad prompt | You waste your morning | The presentation needs fixes |
| Bad context engineering | You break the team’s work | Agent codes without knowing project conventions |
| Bad intent engineering | You break things for the whole organization | Agent optimizes for the wrong metric |
| Bad spec engineering | You break things at company scale | A whole agent system produces inconsistent outputs |
The stakes go up. But so does the value of the work we’re doing. Context engineering and intent engineering can be full-time roles in a large company - and well-paid ones at that.
📋 Discipline 4: Spec engineering - the top of the game
And we arrive at the top of the stack. Spec engineering is the practice of writing documents that autonomous agents can execute over long time horizons without human intervention.
This is the level above everything I’ve described, because the first three disciplines focused on how you prepare the work directly for the agent. Spec engineering is thinking about your organization’s entire body of information as agent-readable, agent-interchangeable material.
Specifications are not prompts. They are:
- Complete - they contain everything the agent needs for execution
- Structured - they have clear, logical organization
- Internally consistent - they contain no contradictions or ambiguities
- Measurable - they define how to assess the quality of the output
A lesson from Anthropic: when a better model isn’t the answer
The Anthropic team struggled with the Opus 4.5 agent while building a production-quality web app. When they gave a general prompt like “build a claude.ai clone,” the agent tried to do too much at once, exhausted its context during implementation, and left the next session guessing what had happened.
The solution was not a better model. It was spec engineering - a pattern in which:
- An initial agent sets up the environment
- A progress log documents what’s been done
- A coding agent makes incremental progress according to a structured plan in each session
The specification became scaffolding that let many agents produce coherent output over days. And despite the move to Opus 4.6, the need for spec engineering didn’t shrink - it grew, because a newer model can do even more work, so it needs even better specifications.
This is counterintuitive but crucial: the smarter models get, the better you have to be at specifying.
From prompt to spec = from conversation to blueprint
This transition mirrors something human engineering has known for decades:
- Building something small? → Verbal instructions and conversations work fine
- Building something big? → You need plans, blueprints, specifications
No one builds a skyscraper from a conversation with the architect. You need detailed plans. And exactly the same now applies to working with autonomous AI agents.
The fractal insight: everything is a specification
And here comes a genuinely fascinating insight that changes the way you think about the whole organization. Spec engineering operates at multiple levels at once:
- 📄 Task level: A spec for a single agent run - a log, a list of requirements, a plan
- 📁 Project level: How we assign work, how we measure progress, how we verify quality
- 🏢 Organization level: The entire body of company documents as agent-readable specifications
And now the key thought:
Your corporate strategy? That’s a specification.
Your product strategy? That’s a specification.
Your OKRs? That’s a specification.
Everything ends up as a specification your agent can use.
This is different from context engineering. Context engineering shapes the context window in a way that matters for the agent. Spec engineering is thinking about the entire structure of corporate documents as a form of specification that agents can read and execute.
And it’s interesting - one-person companies have the biggest advantage here. If you’re a solopreneur and you can just convert your Notion to be agent-readable, you’re already well on your way. You don’t have to transform a giant SharePoint. It’s simple. It’s easy. And it delivers immediate results.
🧩 Five primitives of spec engineering
“Write better specs” sounds rather vague. Fortunately, Nate defines five concrete primitives - the fundamental building blocks that good specifications are made of. Each can be trained separately.
1. 🎯 Self-contained problem statements
Can you state a problem with enough context that the task is plausibly solvable without the agent going out for more information?
This is Toby Lütke’s insight in practice. The discipline of self-containedness forces you to:
- Be clear about what you actually want
- Surface hidden assumptions you normally leave implicit
- Articulate constraints, because you trust that the human on the other side will fill the gaps - but AI doesn’t fill gaps reliably; it guesses in a way that is often subtly wrong
💪 Exercise: Take a request you’d normally handle conversationally, like “update the dashboard to show Q3 numbers,” and rewrite it as if the person receiving it had never seen your dashboard, doesn’t know what Q3 means in your organization’s context, doesn’t know which database to query, and has no access to any information you don’t include. That is the level of self-containedness to aim for.
2. ✅ Acceptance criteria
If you can’t describe what “done” looks like, the agent can’t know when to stop. It will stop at any point its internal heuristics say the task is complete - which may have nothing to do with what you needed.
This is why the “80% problem” is so common in AI work. The agent does 80% of what you want, but the missing 20% is often the most important part.
Instead of: “Build a login page.”
Write: “Build a login page that supports email/password, social login through Google and GitHub, progressive 2FA disclosure, session persistence for 30 days, and rate limiting after five failed attempts.”
Feel the difference? The first version leaves the agent enormous room to “guess.” The second defines exactly what “done” means.
💪 Exercise: For every task you delegate, write three sentences an independent observer could use to verify the result without asking you anything. If you can’t write those sentences - you probably don’t understand the task well enough to give it to an agent. And it’s worth realizing this before you assign the work.
3. 🚧 Constraint architecture
Four categories that turn a loose spec into a reliable one:
| Category | Question | Example |
|---|---|---|
| Obligations | What must the agent do? | ”Always run tests before committing” |
| Prohibitions | What can’t the agent do? | ”Never modify config files” |
| Preferences | What to prefer when several approaches exist? | ”Prefer a simpler solution over an elegant one” |
| Escalation triggers | What to escalate instead of deciding? | ”If a change touches a public API, ask” |
The best claude.md files aren’t long lists of rules. They are concise and high-signal. Every line has to earn its place. The community consensus is clear: if you ask “would removing this line cause the AI to make mistakes?” and the answer is “no, not really” - delete the line.
💪 Exercise: Before delegating a task, write down what a smart, well-intentioned person might do that would technically satisfy the request but produce a bad result. Those failure modes become your constraint architecture. Encode them.
4. 🧱 Decomposition
Large tasks have to be broken into components that can be:
- Executed independently
- Tested independently
- Integrated predictably
This is software engineering’s oldest lesson - modularity - applied to AI task delegation. And it isn’t only about code. An audit of marketing content needs the same decomposition: quality assessment → gap analysis → recommendation generation.
In 2026 you don’t have to manually specify every subtask. You have to supply decomposition patterns that a planner agent can use to break larger work down. Your work increasingly isn’t writing subtasks but supplying patterns by which the agent creates them.
💪 Exercise: Take a project estimated at several days of work and break it into subtasks where each takes under 2 hours, has clear input-output boundaries, and can be verified independently of other tasks. That’s the granularity at which agents work best.
5. 📏 Eval design
How do you know the output is good? Not “does it look reasonable” - which is how most people evaluate AI output - but can you prove measurably, consistently that it’s good?
If prompt craft is the art of input, eval design is the art of knowing whether that input worked. In a world where agents can run for really long stretches, evaluation is the only thing standing between an output you can’t use and an output you can ship as-is.
💪 Exercise: For every recurring AI task, build an eval - 3-5 test cases with known good outputs - and run them periodically, especially after model updates. This will catch regressions, build intuition, and create institutional knowledge of what “good” looks like for your specific use cases.
🗺️ Where to start? Step-by-step progression
If you’re feeling overwhelmed by the amount of new concepts, relax. These four disciplines are a stack - you start from the bottom and build upward. You don’t have to master everything at once.
Step 1: Close the gap in prompt craft 🔨
Most people are worse at basic prompting than they think. Seriously. Concrete moves:
- 📖 Re-read the prompting docs (Anthropic, OpenAI, Google)
- 🗂️ Build a folder of tasks you do regularly
- ✍️ Write your best prompt for each of them
- 📊 Save the results as a baseline
- 🔄 Come back to them over time and improve
Take prompt craft seriously. It’s the foundation everything else stands on.
Step 2: Build a personal context layer 🌐
Write the equivalent of a claude.md for your work - regardless of which model you use. It should contain:
- Your goals and priorities
- Your constraints and preferences
- The quality standards you expect
- Institutional context - the kind a new team member would need 6 months to absorb
- Communication preferences
Start AI sessions by loading this context. The difference in output quality should be immediate and obvious. If it isn’t - your context document needs work.
Step 3: Move into spec engineering 📋
Take a real project (not a toy problem) and write a specification for it before touching AI:
- Self-contained problem statement
- Acceptance criteria
- Constraint architecture
- A decomposition plan
- Evaluation criteria
Pass the spec to an agent and see what comes back. Compare with the result you’d get from a simple prompt. The difference should be striking.
Step 4: Build intent infrastructure 🎯
This is the organizational layer. If you manage people or systems:
- Encode the decision frameworks your team uses by default
- Define what gets escalated by AI vs. what AI can decide autonomously
- Write it down, structure it, share it with agents
- Start thinking of every document as a specification an agent will have to read
If you’re an individual contributor:
- Encode the decision frameworks you understand
- Be the champion who pushes this at the organizational level
- Suggest a team conversation: “Let’s talk about what ‘good enough’ looks like for each category of work”
💡 Why this reaches far beyond AI
And finally - the insight I find the most valuable in Nate’s whole material. The one that makes these four disciplines matter even for people who don’t work with AI day to day.
The ability to supply high-quality input to intelligent systems turns out to be a transferable skill - it works for AI and for humans alike.
Think about this for a moment:
- How many times have you been in a meeting where someone refers to a document, you don’t know which one, and you’re afraid to ask?
- How many times have you been given a task with no clear acceptance criteria and had to guess what “done” means?
- How many times has “politics” at a company really been an undisclosed conflict of assumptions that were never said out loud?
AI forces a communication discipline that the best leaders have always practiced intuitively. Now everyone needs it - because machines don’t let us be lazy in communication.
The best human managers already operate with this kind of clarity - and you can see it in their results:
- They supply full context when delegating tasks
- They state acceptance criteria to their team members
- They articulate constraints and preferences
- They define when an employee should escalate a decision
Doesn’t this sound familiar? These are the four disciplines of prompting applied to humans. And it produces effective leadership.
The prompt by itself is dead. Specification, context, organizational intent - that’s where the value is moving. Because a specification done well turns out to be just what clear thinking has always looked like - made explicit, because machines don’t let us be lazy.
🏁 Summary
Prompting in 2026 is not a single skill - it’s a stack of four disciplines, where each layer enables the layers above:
- 🔨 Prompt craft → The minimum standard. You have to know it, but it won’t set you apart.
- 🌐 Context engineering → Curating the information environment. This is where the real efficiency magic happens.
- 🎯 Intent engineering → Encoding goals and values. Without it, agents optimize for the wrong things.
- 📋 Spec engineering → Writing documents for autonomous agents. The highest and hardest level of the game.
You can’t drop the lower rungs - it’s a stack, not a ladder. You won’t write good specs if you can’t write good prompts. You won’t build effective agent systems without understanding context. You don’t align agent behavior to organizational goals without understanding intent.
But if you master all four? You’ll do a week’s work in one morning. Same model, same Tuesday - but entirely different results.
And a bonus: you’ll become a better communicator, a better leader, and a better collaborator. Because these skills work not only with machines - they work with humans too.
Good luck prompting the humans and the agents in your life. 🚀
🖼️ Visual summary
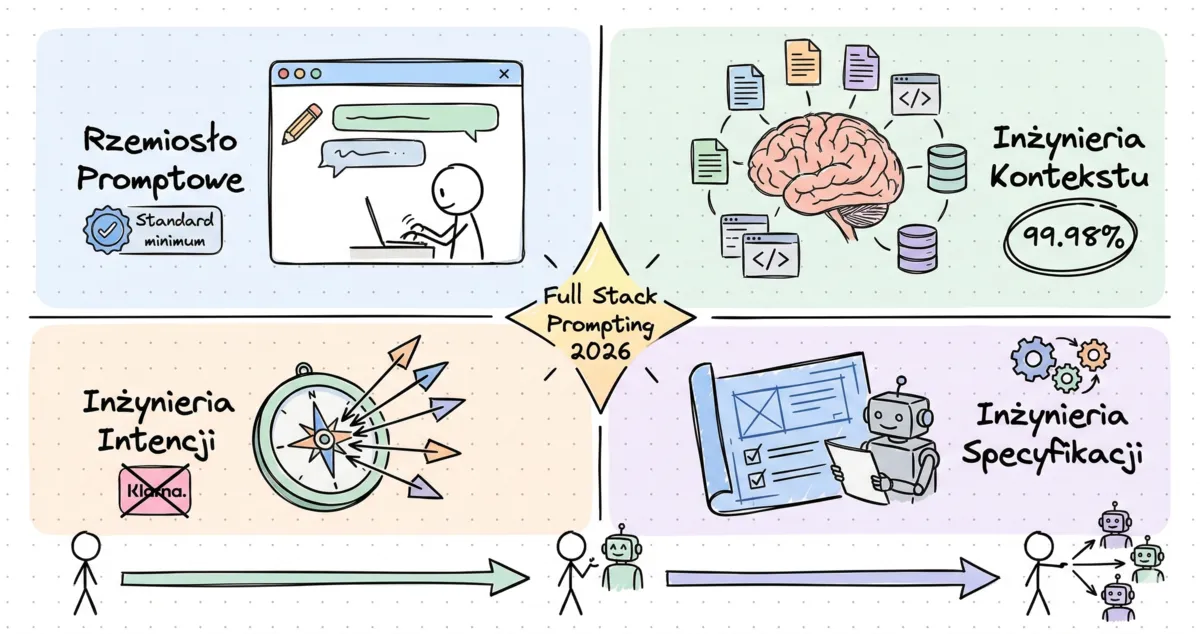 The four disciplines of prompting - from prompt craft to spec engineering.
The four disciplines of prompting - from prompt craft to spec engineering.
📚 Sources
[1] Nate B. Jones. (2026). “Prompting just split into 4 different disciplines”. YouTube. https://youtu.be/BpibZSMGtdY
[2] Anthropic. (2025). “Building effective agents” - context engineering documentation.
[3] Toby Lütke, CEO of Shopify - statements on context engineering as a discipline of communication.
[4] Harrison Chase, LangChain - interview with Sequoia Capital on context engineering.